
從鍛造場回到廚房
上一篇我們把 Anthropic 的《The Founder’s Playbook》反著讀了一遍,拆出了三個沒被明說的設計原則:能力與約束成正比、信任是分層的、記憶的缺失是刻意的。
簡單回顧:Chat 是「不動手的思考夥伴」、Cowork 是「有圍牆的自主代理」、Code 是「能力全開但規矩你自己寫」。三個產品、同一個模型、三套完全不同的邊界設計。
好,知道了。然後呢?
然後就是——帶著這些理解,回到自己的工作場景,順著結構切。
「順著結構切」是什麼意思?就是:不只照行銷文案說的「Chat 適合問問題、Cowork 適合做研究、Code 適合寫程式」這樣表面地分工,而是根據每把刀的鍛造意圖,找到一般使用指南不會告訴你的用法。
這些用法不是什麼密技或 hack,而是只有在你理解設計意圖之後,才看得出來的東西。
Chat:「不動手」這件事,其實是你最大的資產
我發現大部分人對 Chat 的第一反應是覺得它有點「弱」——跟 Cowork 和 Code 比起來,它不能碰檔案、不能連外部系統、什麼都不能「做」,感覺像是三兄弟裡最沒用的那個。
但如果你讀過上篇、理解了 Chat 的設計意圖,就會發現這個想法完全搞反了。
Chat 的限制,恰好是它最值錢的特性。
為什麼?我們從 Playbook 裡的使用建議來反推。
對抗性思考的安全空間
Playbook 裡有一句話,反覆出現到幾乎像口號了:
“Using Claude as structured devil’s advocate is a core use case at every stage of the AI startup life cycle.”
(在 AI 新創生命週期的每個階段,把 Claude 當作結構化的魔鬼代言人,都是核心使用場景。)
而且特別注意——它建議做 devil’s advocate(魔鬼代言人)、做 pressure test(壓力測試)、做 pre-mortem(事前驗屍)的時候,指定使用的工具是 Chat,不是 Cowork,也不是 Code。
為什麼?
因為 Chat 不能動手。
這聽起來像廢話,但你仔細想:當你讓 AI 用最尖銳的角度挑戰你的想法、攻擊你的假設、找出你計畫裡最脆弱的環節——你會希望這個 AI 同時有權限去動你的檔案、改你的程式碼、或發你的信嗎?
當然不會。
Chat 的「無行動力」,在對抗性思考的場景裡反而創造了一個心理安全空間——你可以放心讓它往最極端的方向挑戰,因為無論它說什麼,結果都只是文字。它不會自作主張跑去執行任何東西。你看完可以採用、可以忽略、可以罵它想太多,但它不會在你背後搞事。
(就像找一個嘴巴很毒但手上沒有任何權限的顧問——你可以放心聽他講最難聽的話,因為他除了講話什麼也做不了… XD)
AI 的預設姿態是順從,你得主動翻轉
Playbook 裡面有一段講 confirmation bias(確認偏誤)的,寫得非常直白:
“Ask an AI tool for evidence supporting what you already believe, and it will find it.”
(叫 AI 工具去找支持你既有信念的證據,它就會找到。)
“AI follows your direction, which means a founder who isn’t asking hard questions can now construct an elaborate, well-researched-looking case for a bad idea faster than ever before.”
(AI 順著你的方向走,這意味著一個不問難問題的創辦者,現在可以用前所未有的速度,為一個爛點子建構出一套看起來研究充分的完整論述。)
這段話翻成我們的刀匠比喻就是:Chat 預設是一面順著你照的鏡子。你問什麼方向,它就往什麼方向找答案給你。你覺得自己的點子很棒,它會幫你找到二十個理由證明你是對的。
而且找出來的東西還有模有樣的,不像隨口敷衍——這才是最危險的地方。
Playbook 的建議是:同一個工具,用在反方向就能變成解藥。你必須主動把 Chat 從「支持模式」切換到「對抗模式」,它才會幫你找反面證據、挑你的假設、質疑你的數字。
這個主動切換的動作,不是 AI 會幫你做的。它是你的責任。
「想錯了也沒事」的零成本試驗場
最後一點可能是最容易被忽略的。
正因為 Chat 什麼都不能「做」,它反而是最安全的犯錯空間。
你可以把一個還沒成形的想法丟給它拆解、把一個八字還沒一撇的假設交給它壓力測試、甚至故意提出一個你覺得可能不對的方向讓它幫你驗證到底哪裡不對。拆完如果覺得不行?那就不行,下一個。零成本。
如果同樣的事拿到 Code 裡面做呢?它可能已經幫你蓋了三百行你根本不要的程式碼,而且蓋得還挺漂亮的,讓你捨不得刪…
(這感覺就像 RPG 裡的存檔機制——Chat 是那個讓你隨時讀檔重來的地方,Code 是已經打了半小時沒存檔的 Boss 戰。你確定要在 Boss 戰裡面測試新戰術嗎…?)
Cowork:連接器不是功能開關,是信任邊界
大部分人設定 Cowork 的時候,看到可以連 Gmail 就連 Gmail、看到可以連 Google Drive 就連 Google Drive,覺得「能連的都連上,功能開越多越好嘛」。
但如果你帶著上篇的理解來看——每一個連接器的背後,代表的是你擴大了 AI 在你數位生活裡的行動範圍——這件事的意義就完全不一樣了。
連接器配置就是信任設計
開一個 Gmail 連接器,意味著 Cowork 可以讀你的信件、幫你寫回覆、管理你的信件流。開一個 Google Calendar 連接器,意味著它可以讀你的行事曆、幫你排會議。
每一個「開」的動作,都是你把一個新的房間鑰匙交出去。
Playbook 裡 Cowork 的使用場景,每一個都是先定義好任務需要碰哪些系統,然後才開對應的連接器。不是「先全開,再看看能做什麼」,而是「先確認需要什麼,再開什麼」。
順序不能反。
我知道這聽起來有點像在講資安常識——最小權限原則嘛,做資訊的人都知道。但這裡的重點不只是安全性,而是使用品質。
當你連了太多不相關的系統,Cowork 的「行動空間」變得太大,它在執行任務的時候反而更容易飄——因為可碰的東西太多,它得自己判斷哪些該碰哪些不該碰。你把判斷責任推給了 AI,但上篇我們就看過了,Anthropic 的設計邏輯恰好是反過來的:判斷責任應該在人這邊。
簡單來說:連接器開得精準,Cowork 表現更穩。少即是多。
排程的真正意義:你不在的時候,它還在你畫的圈裡
Playbook 裡提到 Cowork 的一個重要能力是排程——比如每週一早上自動拉數據生成 KPI 週報、定期追蹤回饋信件、自動更新追蹤表等等。
排程這件事,很多人覺得就是「設個定時任務嘛,方便」。但從信任設計的角度想,排程的本質是:
在你不在的時候,AI 仍然在運作。
在你睡覺的時候、在你開會的時候、在你放假的時候——它會按照排程自己跑起來,碰你授權它碰的系統,產出你設定它產出的東西。
所以排程的前提是:你對 AI 的行動範圍非常確定。你得很清楚地知道它會碰什麼、從哪裡拉資料、產出格式是什麼、不會碰什麼。
如果連接器開得太寬又設了排程,那就等於你在睡覺的時候讓一個行動範圍模糊的代理人替你幹活。不是說一定會出事,但你醒來看到成果的時候可能會「咦!?這東西哪來的?」
(就像你交代實習生「每週一幫我整理信箱」,但忘了說「只整理工作信箱」,然後某天他把你的私人信件也一起歸檔了… 技術上他沒做錯,但你還是想翻桌)
Cowork 是中間層,不只是另一個工具
Playbook 裡有一個容易被忽略的使用模式:三個產品之間的產出流轉。
比如文件建議的流程是這樣的:
- 用 Chat 做完假設壓力測試,確認方向
- 用 Chat 定義完架構原則,產出 CLAUDE.md
- 用 Code 根據 CLAUDE.md 去建造
- Code 跑完安全性審計,產出報告
- 審計報告拿回 Chat 做判斷和優先排序
- 然後 Cowork 接手持續性的工作——使用者回饋收集、週報生成、排程監控
在這個流程裡,Cowork 扮演的角色不是「另一個可以用的工具」,而是Chat 和 Code 之間的橋——把 Chat 的思考成果落地成可交付的文件,把 Code 的技術產出轉化成營運層面可以持續追蹤的流程。
理解了這一點,你就不會再把三個工具當成三個獨立的東西來用了。它們是一個循環。
Code:CLAUDE.md 不是文件工作,是你最重要的產品
好,到了 Claude Code。上篇我們分析了它的設計哲學是「能力全開,約束由人提供」。那具體來說,「提供約束」這件事應該怎麼做?
Playbook 裡其實講得相當細,而且它建議的順序跟大多數人的直覺完全相反。
先寫契約,再動工
大部分人(包括以前的我自己,說來慚愧)拿到 Claude Code 的第一個反應是:「太好了,來寫 code!」然後就開始描述功能、讓它生成程式碼、跑起來看看對不對、不對再改。
Playbook 說:不對。順序反了。
它建議的流程是:
- 先在 Chat 裡,描述你要建什麼、解決什麼問題、預期的規模——用 Chat 把架構原則、設計取捨、要避免的依賴全部想清楚
- 存成 CLAUDE.md——這是你跟 Claude Code 之間的行為契約
- 然後才打開 Code 開始建造
原因很直接:
“Without this context, each session starts from scratch and Claude Code is forced to infer its own structural assumptions.”
(沒有這份上下文,每次工作階段都從零開始,Claude Code 只能自己推測結構假設。)
注意用詞——「forced to infer」(被迫推測)。不是「自由發揮」,是「被迫猜」。
因為 Code 沒有跨 session 記憶,如果你不提供架構上下文,它每次啟動都得自己猜這個專案「應該長什麼樣」。第一次猜的結果可能不錯,第二次可能也還行,但到了第十次、第二十次——每次猜出來的方向都會有微妙的偏差。
累積起來,你的 codebase 就像一棟由二十個不同建築師各自蓋了一間房間的房子。每間房間單獨看都還可以,但合在一起… 嗯。
(這大概就是所謂的「技術負債 by AI」?以前是工程師亂搞留下的債,現在是沒人告訴 AI 方向讓它自己亂猜留下的債… 不知道哪種比較慘 XD)
五分鐘的保險
Playbook 有一個非常具體的建議:
“Five minutes of documentation per session is cheap insurance against architectural drift.”
(每次工作結束花五分鐘寫文件,是防止架構偏移最划算的保險。)
每次 Code session 結束的時候,花五分鐘更新 CLAUDE.md:這次做了什麼決定、為什麼這樣做、引入了什麼新的假設。
五分鐘。
聽起來沒什麼,但大多數人不會做。因為剛寫完一段 code,跑起來沒問題,心裡想著「太好了,這段搞定」,然後就關掉去做別的事了。
問題是:你腦子裡記得這次 session 做了什麼決定,但 Claude Code 不記得。下次它打開的時候,如果 CLAUDE.md 沒有更新,它讀到的還是舊版本的「行為契約」。你的認知跟它的認知就開始出現落差。
幾次之後,你會開始遇到一種很奇怪的狀況:你跟 Code 說「接著上次的進度」,但它做出來的東西跟你預期的方向不太一樣。不是因為它變笨了,而是因為它根本不知道「上次的進度」長什麼樣。
所以那五分鐘,不是在「寫文件」,而是在維護你跟 AI 之間的共識。
能跑 ≠ 安全
最後一點,Playbook 講得非常直白,我覺得值得原文引用:
“Agentic coding tools generate code that works, not code that is inherently secure.”
(AI 程式碼工具產生的是能跑的程式碼,不是天生安全的程式碼。)
“Security vulnerabilities are invisible until they’re exploited, which means there’s no natural feedback loop to alert a first-time founder that something is wrong.”
(安全漏洞在被利用之前是看不見的,這意味著沒有天然的回饋機制來提醒你哪裡有問題。)
這是製造者自己在說自己的工具的限制。你生成的 code 能跑、能通過測試、功能看起來完全正確——但這不代表它是安全的。因為「能跑」有即時的回饋(跑不起來你馬上知道),安全性沒有(被攻擊之前你不會知道)。
Playbook 的建議是:在任何真實使用者接觸到你的產品之前,用 Claude 自己做一輪安全性審查——包含身份驗證、session 處理、API 回應裡的資料外洩、輸入驗證和注入風險、有已知漏洞的依賴套件。
注意:它建議你用 Claude 來審查 Claude 生成的 code。這不是矛盾,而是因為生成和審查是兩個不同的任務模式。生成的時候模型專注在「怎麼讓功能跑起來」,審查的時候你把它的注意力導向「這段 code 有什麼可以被攻擊的地方」。同一個模型,不同的提示方向,產出完全不同的結果。
(嗯,又回到了 Chat 那一段的核心概念——AI 的預設姿態是順從的,你把它指向哪裡,它就看哪裡。所以安全性審查不能「順便」,得專門做。)
三把刀的協作流:產出即輸入
聊到這裡,其實你應該已經發現了——三個工具之間有一個 Playbook 從頭示範到尾、但從未單獨拎出來講的模式:
每一個工具的產出,都是另一個工具的輸入。
讓我把 Playbook 裡描述的完整流程整理出來:
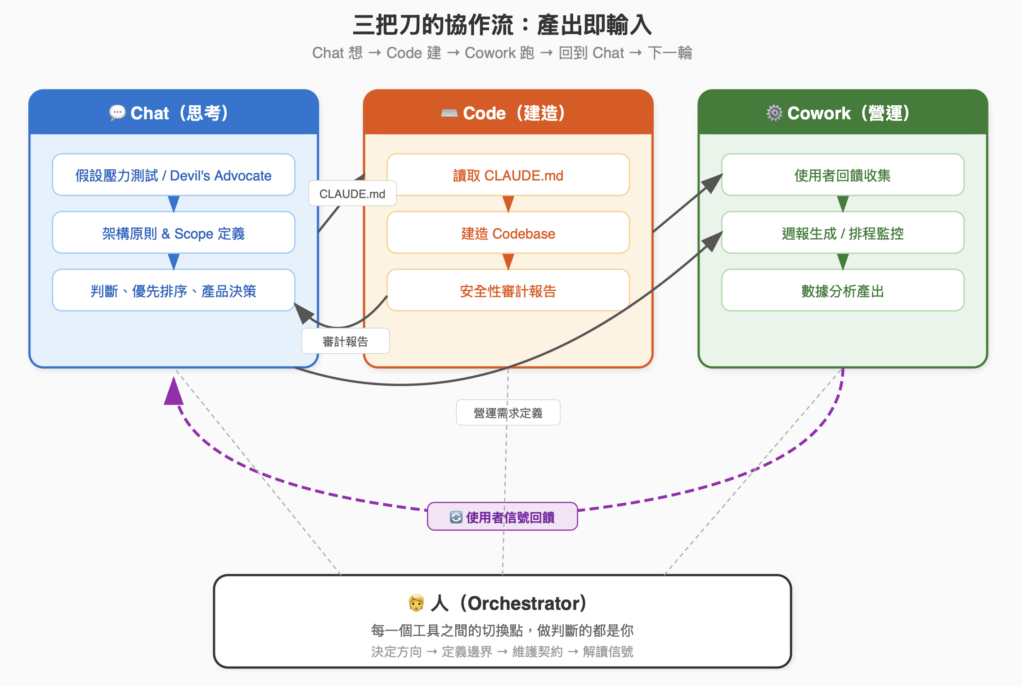
這不是三個獨立工具的拼盤,而是一個循環系統。而驅動這個循環的——請注意——不是任何一個工具本身。
是你。
你決定什麼時候從 Chat 切到 Code。 你判斷 Code 產出的審計報告哪些問題要先修、哪些可以等。 你決定 Cowork 的排程該拉什麼數據、送到哪裡。 你判斷 Cowork 收集回來的使用者回饋,哪些是真正的信號、哪些是雜訊。
三個工具各自有不同的能力和邊界,但在工具和工具之間的每一個切換點,做判斷的都是你。
Anthropic 把這個角色叫做 “orchestrator of agents”(代理人的指揮者)。我覺得這個說法還蠻貼切的——你不用自己上場打每一個位置,但你得決定誰上場、什麼時候換人、以及比賽策略是什麼。
握刀的是你自己
好,兩篇文章聊下來,我們從 Anthropic 的 Founder’s Playbook 裡面拆出了不少東西。
上篇我們反著讀,看到了三條產品線背後的邊界設計圖——能力與約束成正比、信任是分層的、記憶的外化是刻意的安全機制。
這篇我們順著讀,把這些設計意圖轉化成實際的使用原則——Chat 的「不動手」是資產不是缺陷、Cowork 的連接器是信任邊界不是功能開關、Code 的 CLAUDE.md 是行為契約不是附帶文件。
但說到底,整份 Playbook 最重要的一句話,可能是最容易被略過的那句:
“The bottlenecks are no longer what you can build, but what you choose to build.”
(瓶頸不再是你能建什麼,而是你選擇建什麼。)
工具已經強大到幾乎什麼都能幫你「做」。但「做什麼」「為什麼做」「什麼時候該停」——這些問題,從頭到尾都是人的問題。
AI 工具能放大你的判斷力,但不能替你判斷。它能幫你跑得更快,但不能幫你決定該往哪個方向跑。
刀再好,握刀的終究是你自己。
順著結構切,效果大發揮~
參考文件:
The Founder’s Playbook: Building an AI-Native Startup(PDF) — Anthropic, 2026.05
本文為系列文章下篇。上篇:「製造者的說明書要反著讀——從 Founder’s Playbook 反推 Claude 產品線的邊界設計」


